2022-01-21
2022-01-21

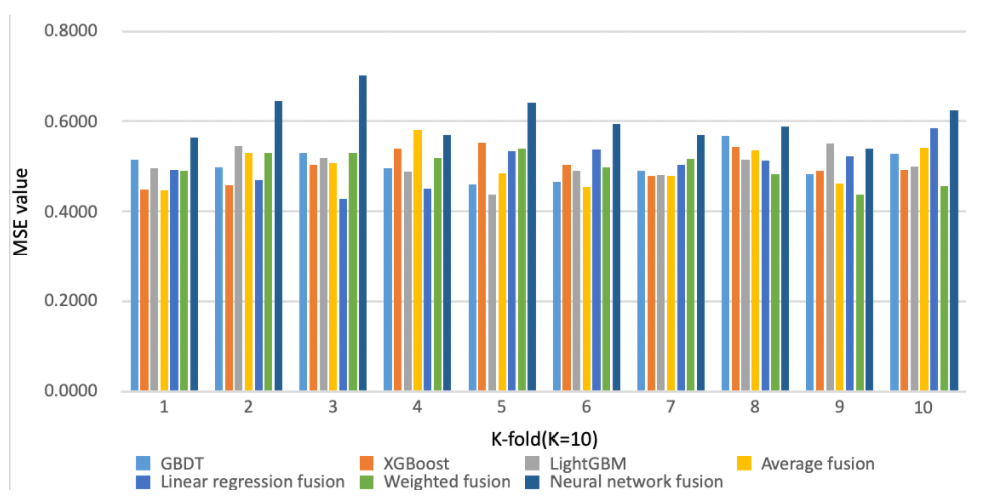
In today's society, happiness has attracted more and more attentions from researchers. It is interesting to study happiness from the perspective of data mining. In psychology domain, the application of data mining gradually becomes widespread and popular, which works from a novel data-driven viewpoint. Current researches in machine learning, especially in deep learning provide new research methods for traditional psychology research and bring new ideas. This paper presents an empirical study of learning based happiness predicition approaches and their prediction quality. Conducted on the data provided by the "China Comprehensive Social Survey (CGSS)" project, we report the experimental results of happiness prediction and explore the influencing factors of happiness. According to the four stages of factor analysis, feature engineering, model establishment and evaluation, this paper analyzes the factors affecting happiness and studies the effect of different ensembles for happiness prediction. Through experimental results, it is found that social attitudes (fairness), family variables (family capital), and individual variables (mental health, socioeconomic status, and social rank) have greater impacts on happiness than others. Moreover, among the happiness prediction models established by these five features, boosting shows the most effective in model fusion.
Keywords:Happiness prediction; factor analysis; machine learning; model fusion
当今社会,研究者们越来越关注幸福感。从大数据角度来研究幸福感是一项非常有趣的工作。在心理学领域,大数据的应用越来越广泛,其从一种全新的数据驱动的视角进行心理学分析。目前机器学习研究方面的进展,尤其是深度学习,为传统心理学研究提供了新的研究方法。本文通过实验对比分析了一系列基于机器学习的幸福感预测方法及其融合预测质量。利用“中国综合社会调查”(CGSS)项目提供的数据,本文给出了各种幸福感预测方法的实验结果并探究了影响幸福感的因素。从特征工程、预测建模和预测评价等三个阶段,本文讨论了影响幸福感的相关因素并研究了不同结果融合模型对幸福感预测的效果。实验结果表明对幸福度影响比较大的因素包括社会态度(公平性)、家庭变量(家庭资本)和个体变量(心理健康、社会经济状态以及社会地位)。此外,通过这五种特征建立的幸福感预测模型中,boosting在模型融合中效果最好。
关键词:幸福感预测、因素分析、机器学习、模型融合